Managing baby names and data projects with Github
We learn the ropes of managing data projects in Github and proper data workflow, so that we don’t run into troubles with lost code/data/unpredictable behavior. And, as a sample project, we’ll use Unix filters and the U.S. Social Security Administration’s data on most popular baby names, to find out which baby name had the single most popular year for every given state.
Deliverables
A project folder in your compciv Github repo
In your compciv repo, create a subdirectory (from the command-line) named:
homework/test-babies
By the end of this assignment, it should contain two files:
top-babies-counter.shhelper.sh
The `helper.sh` script to download and unpack the baby name data
The helper.sh script, when executed, should download the zip file of baby names here and unzip it into a directory named data-hold/ (which, if you read later in this tutorial, will not be part of the actual repo).
The zip file contains a list of baby names per U.S. state (including Washington D.C.)
The `top-babies-counter.sh` script to find the top baby name per state in each state's history
The top-babies-counter.sh script, when executed, should for every state file, print out the line which contains the most popular baby name (in a single year) in that state’s history. It also assumes that helper.sh was able to execute and download the data successfully.
Walkthrough
Did you read the Deliverables section and not have a clue what you're supposed to do? That's OK: the purpose of this project is not just to count baby names, but to go through the motions of setting up a proper data project, that is both easy for you to develop and maintain, and for me (and you) to debug, if necessary.
There's not much thinking involved here, as I walk you through all the steps exactly to get the end result. But I do want you to be observant about what's going on, such as, how the data ends up being organized. How your work gets saved onto Github. And how, with a little upfront organization, you can prevent a lot of the "Where did I put my data?" problems that tend to make life way more difficult than necessary.
Overall objectives
When you finish this exercise, you will end up with:
- A repo named
compcivattached to your Github account (if you don't have it already) - A clone of that repo, located at
~/compcivon yourcorn.stanford.eduspace - And inside that repo, you'll have a
homeworksubdirectory, from which you will be storing your work into. For this assignment, your work will be in thehomework/test-babiesdirectory.
You can see a sample finished repo here (my Github username is hello-stanford):
https://github.com/hello-stanford/compciv/tree/master/homework/test-babies
If you were to clone your compciv repo to your personal laptop and open it up via your operating system, it would look something like this:

So what follows will seem like a lot of highly detailed steps. That's fine, after a couple more actual assignments/projects, you'll see the pattern and purpose.
(and again, don't just copy and paste. Actually type out the commands and see what they do for yourself)
Setting up the compciv Github repo
Assuming you've created a Github account, all the steps needed to create the compciv repo, via Github's web interface, can be found in this tutorial. The tutorial will also walk you through the process of adding/committing/pushing to Github, but I'll repeat those same steps in this tutorial.
Did you finish the tutorial?
Do these two things exist?
- The repo at https://github.com/YOUR_GITHUB_NAME/compciv
- The cloned repo/directory
~/compcivon your corn.stanford.edu space
Then carry on.
A quickie preventive step
A quick aside: At the end of this exercise, you'll have downloaded a bunch of baby name data that I do not want – I just want to see the code you used to get that data. If you follow the steps in the tutorial, you'll have created a data-hold/ directory.
To prevent that data-hold/ from becoming part of your actual compciv Github repo, we will ignore it by specifying it in the .gitignore configuration file.
Just perform the steps below. You should only have to do this once for the entirety of your repo's existence:
First, log into corn.stanford.edu. Then run these commands:
cd ~/compciv
# you only have to do this ONCE...as gitignore affects all the folders
# within ~/compciv
echo 'data-hold/' >> .gitignore
####
# Now create the folder for *this* assignment
Getting into the homework
OK. At this point, you should still be logged into corn.stanford.edu
Now we'll set up the subdirectory in which we'll do all of our work for this assignment.
In these next steps, we will:
- Change into
~/compciv(for the purposes of this tutorial, and the rest of this class, I'm assuming your cloned repo is named "compciv" and lives right under your "home" directory on corn.stanford_edu) - Create the subdirectory
homework/test-babies(homework/will be created if it doesn't already exist) - Create a file named "
README.TXT"
cd ~/compciv
mkdir -p homework/test-babies
touch homework/test-babies/README.txt
# let's add some text to README.txt
echo 'Hello babies' >> homework/test-babies/README.txt
At this point, the directory structure of your Github compciv repo (and your cloned version of it on corn.stanford.edu) should look like this:
compciv/
|
|__homework/
|__test-babies
|___README.txt
Make our first push to Github
Note: Again, if you haven't done looked at the guide on setting up a git repo with Github, check that out first. Especially the part about using a personal access token before pushing things to Github.
Before we change into our homework directory, let's push the changes we've made in compciv/ so far to Github. Remember, all we've done is create a directory named homework/test-babies and added a file named README.txt.
Run git status and you should see something like this:
Untracked files:
(use "git add <file>..." to include in what will be committed)
homework/
(It might be a little different if homework/ already existed, then you might see homework/test-babies, or another variation)
Let's add these changes, and then commit them:
git add --all
git commit -m 'My first commit to test-babies'
You'll see a boilerplate response and you should probably see this message, which indicates that homework/test-babies/README.txt was indeed created
create mode 100644 homework/test-babies/README.txt
So it's not worth explaining all the intricacies of git and Github, but I'll point out one important thing: nothing we've done so far has been sent to our online repo as it exists on github.com/youraccount/compciv. We can keep making changes to the repo, and add and commit to our hearts content. It is only when we try to push our changes does the online repository get affected.
Now, push our changes to github.com:
git push
You should see output similar to this (my username here is hello-stanford):
Counting objects: 6, done.
Delta compression using up to 16 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (5/5), 392 bytes | 0 bytes/s, done.
Total 5 (delta 1), reused 0 (delta 0)
To https://hello-stanford:99999999@github.com/hello-stanford/compciv.git
b761018..35fa073 master -> master
And when you visit your repo at:
https://github.com/YOURUSERNAME/compciv
You should see something similar to this:
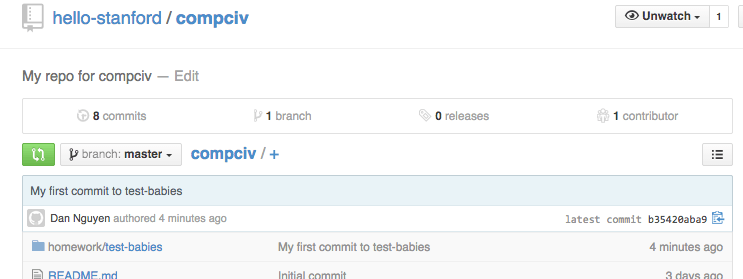
Congrats, you just pushed something into your Github repo. If you want to test out the process again, just make some more random files, add + commit them, then push, and see the changes on the Github website.
You can even delete those files, and do the same process (think of it as adding changes to the git repo, not necessarily adding files):
rm homework/test-babies/README.txt
git add --all
git commit -m "bye bye readme"
git push
Did you accidentally delete something? One of the main features of git and Github is to have a permanent, revisitable record of everything you've done, so no worries (though, you should also think of the implications here, including the problems that come about if you accidentally push something you don't want to be seen).
Just to keep the next few steps a little more uniform, do me a favor and add a random empty text file to the homework/test-babies subdirectory, and add/commit/push to Github:
touch homework/test-babies/hi-dan.txt
git add --all
git commit -m "Here you go dan"
git push
Creating helper.sh
Now onto the assignment. The first logical step is to create helper.sh, which will be the script that just sets things up, i.e. downloads the data.
We want to create helper.sh (and the rest of our homework) in the homework/test-babies subdirectory we created before, so let's cd into there:
cd ~/compciv/homework/test-babies
Now let's think through helper.sh: it's a script that simply downloads the zip file of SSA baby names by state and unpacks it into the data-hold directory.
The data can be found here:
http://stash.compciv.org/ssa_baby_names/namesbystate.zip
So imagine you've finished writing your helper.sh and saved it into the ~/compciv/homework/test-babies directory. You would then execute it like this:
bash helper.sh
And then, this would happen:
helper.shcreates a subdirectory nameddata-holdhelper.shchanges into thedata-holdsubdirectoryhelper.shdownloads the zip filehelper.shunzips the zip filehelper.shreturns to the parent directory from whence it came, i.e.~/compciv/homework/test-babies
After you've finished executing helper.sh, these conditions would be met:
- Inside of
test-babiesis a subdirectory nameddata-hold - Inside of
test=babies/data-holdis the downloaded zip files and a bunch of text files that were unzipped. - Your current working directory should be
~/compciv/homework/test-babies
See if you can think through the steps before looking at the answer below.
# first, make the data-hold subdirectory if it doesn't already exist
mkdir -p data-hold
# then change into data-hold so that the data is downloaded there
cd data-hold
# download the file into the current directory, i.e. data-hold/
curl -o namesbystate.zip http://stash.compciv.org/ssa_baby_names/namesbystate.zip
# unzip the file; it should dump the data into your current location, i.e.
# the data-hold/ directory
unzip namesbystate.zip
# go back to the parent directory, i.e. ~/compciv/homework/test-babies
cd ..
So to reiterate: if you write the code above and then save it into a file at:
~/compciv/homework/test-babies/helper.sh
– and then execute it (again, you should still be in the test-babies directory):
bash helper.sh
The steps and effects outlined above should just happen. Try it once.
rm, repeat
When you've confirmed that it works – i.e. it creates a data-hold/ subdirectory and downloads the data into it – why not try it again? You can delete that data-hold directory, via:
# first, run a `ls` command to make sure you are pointing to the righ tthing:
ls data-hold
# take a deep breath, and slooowly type out:
rm -r data-hold
And then run bash helper.sh again, just to see how nice and predictable and deterministic it is, which is the way computing should be. The upshot here is, if I download your helper.sh script and run it on my own computer, I'll be in the same relative setup as you are, with the same data and directory structure.
Push helper.sh
At this point, the structure of your compciv repo, starting from the top, will look like this:
compciv/
|
|__homework/
|__test-babies
|___README.txt
|___helper.sh
|___data-hold
|__(a bunch of TXT files)
Now that we've written some real code, let's add/commit/push the changes to Github. To do that, let's move back up to the ~/compciv directory.
Again (and I'm just going to reiterate it for this lesson, in future lessons, you should just know where you are), I'm assuming you're in the homework/test-babies subdirectory. In which case, you can move back up to ~/compciv in a relative fashion:
cd ../..
Or, to just get there via an absolute fashion:
cd ~/compciv
At this point, let's run git status to see what we'll be adding to the Github repo. You should just see this (if you followed my steps, exactly, up to this point):
homework/test-babies/helper.sh
If you see:
homework/test-babies/data-hold/
Then you need to do this:
echo 'data-hold/' >> .gitignore
This configures your repo to ignore changes made in data-hold. The reason may be hard to intuit, but think it through: if your helper.sh gets the data, no matter what…then why do you need to commit the data as part of the project? You can assume that I can run helper.sh myself, on my own computer.
Now, it doesn't hurt to commit the raw data. But it's unnecessary, and it also causes your repo to bloat up. So this is why we configure that .gitignore file (which lives at ~/compciv/.gitignore).
So if everything is good to go, you can repeat the git add/commit/push commands, and check out Github.com to see the changes:
git add --all
git commit -m "helper.sh was made"
git push
Making top-babies-counter.sh
OK, now move back into the homework assignment directory to continue the work:
cd homework/test-babies
Let's revisit the actual objective for the top-babies-counter.sh script:
For every state, print out the line which contains the most popular baby name (in a single year) in that state's history
So if IA.TXT looks like this:
IA,M,1952,Roland,16
IA,M,1952,Wendell,16
IA,M,1953,Roland,42
IA,M,1953,Wendell,30
– our script should pick out:
IA,M,1953,Roland,42
And since there are 51 states (including DC), the final output will have 51 lines.
Try to think of the answer yourself. Work through it with the command line. And for the purpose of this exercise, do it from the working directory of ~/compciv/homework/test-babies/ – which means you have to refer to the subdirectory data-hold/.
For example, to just list the .TXT files in data-hold, do this:
ls data-hold/*.TXT
Which should give you an output like this:
data-hold/AK.TXT data-hold/ID.TXT data-hold/MT.TXT data-hold/RI.TXT
data-hold/AL.TXT data-hold/IL.TXT data-hold/NC.TXT data-hold/SC.TXT
data-hold/AR.TXT data-hold/IN.TXT data-hold/ND.TXT data-hold/SD.TXT
data-hold/AZ.TXT data-hold/KS.TXT data-hold/NE.TXT data-hold/TN.TXT
data-hold/CA.TXT data-hold/KY.TXT data-hold/NH.TXT data-hold/TX.TXT
data-hold/CO.TXT data-hold/LA.TXT data-hold/NJ.TXT data-hold/UT.TXT
data-hold/CT.TXT data-hold/MA.TXT data-hold/NM.TXT data-hold/VA.TXT
data-hold/DC.TXT data-hold/MD.TXT data-hold/NV.TXT data-hold/VT.TXT
data-hold/DE.TXT data-hold/ME.TXT data-hold/NY.TXT data-hold/WA.TXT
data-hold/FL.TXT data-hold/MI.TXT data-hold/OH.TXT data-hold/WI.TXT
data-hold/GA.TXT data-hold/MN.TXT data-hold/OK.TXT data-hold/WV.TXT
data-hold/HI.TXT data-hold/MO.TXT data-hold/OR.TXT data-hold/WY.TXT
data-hold/IA.TXT data-hold/MS.TXT data-hold/PA.TXT
To read the first 5 lines of IA.TXT:
cat data-hold/IA.TXT | head -n 5
IA,F,1910,Helen,249
IA,F,1910,Mary,239
IA,F,1910,Dorothy,185
IA,F,1910,Mildred,162
IA,F,1910,Ruth,155
To get the top name/year for IA.TXT. then:
cat data-hold/IA.TXT | sort -n -r -t ',' -k 5 | head -n 1
Answer:
IA,F,1947,Linda,2365
(Try doing this yourself, testing out what each option for sort does, particularly -t and -k and -n)
All together
There's several ways to get the actual answer. I think the most direct way is to use a for loop through the output of ls data-hold/*.TXT, using command substitution, i.e. $(whatever your command is here):
for txtfile in $(ls data-hold/*.TXT)
do
cat $txtfile | sort -n -r -t ',' -k 5 | head -n 1
done
And that should get you all 51 top names. What's interesting is that the top years seem to be decades ago. You'd think that as America gets bigger and bigger, more babies would have a given name in the later years, but that's not the case. Why do you think that's so?
The very top name/year/state is:
NY,M,1947,Robert,10025
Which seemed low to me, so I used a grep just to verify that number. Try it yourself:
cat data-hold/*.TXT | grep -oE ',[0-9]{5,}'
Anyway, looks like we're done. So open/create a file (again, you should be working from ~/compciv/homework/test-babies still; we didn't change directories in the previous steps):
nano top-babies-counter.sh
Then add the program that we just wrote (yes, you could copy and paste, but you should probably just type it out for practice):
for txtfile in $(ls data-hold/*.TXT)
do
cat $txtfile | sort -n -r -t ',' -k 5 | head -n 1
done
Save top-babies-counter.sh. And then re-run it, as many times as you'd like, to see that everything is nice and deterministic and what you expected:
bash top-babies-counter.sh
# over and over again!
for whatev in $(seq 1 10)
do
echo "------------------------"
echo "Doing test run number $whatev, because why not"
echo "------------------------"
bash top-babies-counter.sh
done
Once you're satisfied, it's time to push that code (you can run git status to see what's changed):
cd ../.. # get back to ~/compciv
git add --all
git commit -m 'All done!'
# btw, best to stick with single quotes in messages if you tend to
# be emotive in your commit messages...
git push
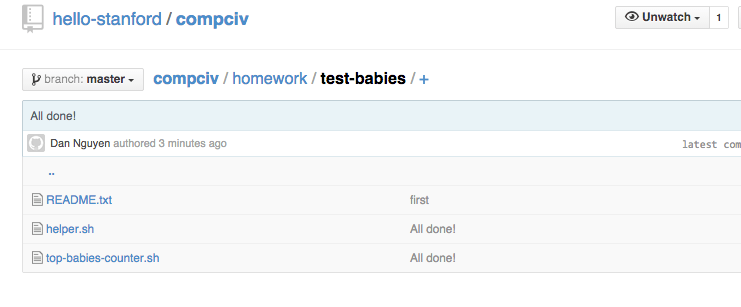
Visit your compciv repo on the Github website. When you navigate to the homework/test-babies subdirectory, it should look something like this (note the absence of data-hold):
Cloning for fun
Let's test out the "theory" of git and Github. In fact, you can feel like what it is to be me, the class grader, when I go through your Github homework folders, download your code, and run it myself to see if it works for me as it did for you (please try not to include any code that would rm -rf my hard drive, or you will be docked points).
Somewhere (don't do this in the root /tmp folder, as you may expose your personal access token in the git repo…) in your home directory, make a throwaway subdirectory:
mkdir ~/my-throwaway && cd ~/my-throwaway
Then clone your compciv repo as you may have done in a previous tutorial:
If your Github repo is public (which it is, by default), then this should work:
git clone https://github.com/YOUR_USERNAME/compciv.git
Otherwise, make reference to your personal access token:
git clone https://YOUR_USERNAME:$GITHUB_ACCESS_TOKEN@github.com/YOUR_USERNAME/compciv.git
That clone action should create a new subdirectory named compciv. Change into that subdirectory and into `homework/test-babies:
cd compciv/homework/test-babies
Run ls to confirm that your helper.sh and top-babies-counter.sh scripts are there. And then run them:
bash helper.sh
bash top-babies-counter.sh
Did everything work as before? (if it didn't, try to figure out why, if you made a mistake earlier. Or just email me)
If it did, which it should, then hopefully you've seen the benefits of a little project management. You've not only solved a homework problem, but you've managed it in a way that you have an online, up-to-date copy of it, and you've abstracted it enough so that you, me, anyone can just clone your repo and run your code and get the exact same result that you did.
It seems like a lot of steps to memorize, but it'll get easier in time, especially as you slow down and think about what each step is doing for you. With a little organization, you make it much easier to debug your own code and, somewhat just as importantly, reduce the risk that you wipe out your work accidentally.
Speaking of wiping out your work…if ~/my-throwaway/compciv is just a "clone", then we should be able to "kill" it without affecting either ~/compciv or the repo as it exists on Github.com, right?
Only one way to find out (be sure not to make any typos):
rm -rf WARNING: Never, ever run rm -rf without taking a deep breath and counting at least to 10. This command, if you run it in the wrong place, will wipe out everything in that "wrong place". At the very least, run hostname && pwd to make sure you're in the correct directory.
rm -rf ~/my-throwaway/compciv